一个容易理解的对比:React 是用来取代Jquery的,那么Flux 就是以替换Backbone.js/Ember.js等MVC一族框架为目的的。
要了解Redux,首先要从Flux 说起。可以认为Redux 是Flux思想的另一种实现方式。通过了解Flux、我们可以知道Flux一族框架贯彻的最重要的观点--单向数据流,更重要的是我们可以发现Flux框架的缺点,从而更深刻的认识到Redux相对于Flux的改进之处。
MVC 框架的缺陷
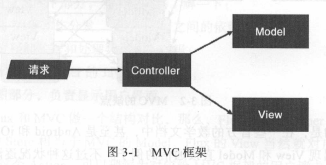
MVC框架把应用分为三个部分:
- Model 负责管理数据,大部分业务逻辑也应该放在Model中;
- View 负责渲染用户界面,应该避免在View中涉及业务逻辑;
- Controller 负责接受用户输入,根据用户输入调用对应的Model部分逻辑,把产生的数据结果交给View部分,让VIew渲染出必要的输出。
实际使用中的MVC:前端MVC往往为了操作方便允许View 和Model直接对话,将造成复杂的网状依赖关系,使局面失控。
对于MVC框架,为了让数据流可控,Controller 应该是中心,当View要传递消息给Model时,应该调用Controller的方法,同样,当Model需要跟新View时,也应该通过Controller。
Flux 框架
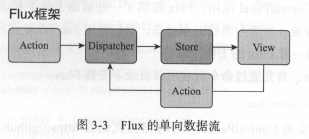
Flux 应用的四个部分:
- Dispatcher ,处理动作分发,维持Store之间的依赖关系;
- Store ,负责存储数据和处理数据相关逻辑;
- Action,驱动Dispatcher 的js 对象;
- View ,视图部分,负责显示用户界面。
在 MVC框架中,系统能够提供什么什么样的服务,通过Controller 暴露的函数来实现。每增加一个功能,Controller 往往就要增加一个函数;在Flux的世界里,新增加功能并不需要Dispatcher增加新的函数,实际上,Dispatcher自始至终只需要暴露一个函数Dispatch,当需要增加新的功能时,要做的是增加一个新的Action类型,Dispatcher对外的接口不用改变。

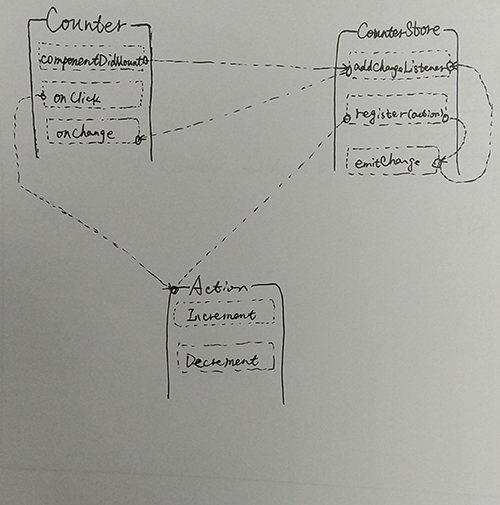
CounterStore.js 通过注册action自负责自身的数据变更,Counter组件通过事件派发action,触发CounterStore.js 维护的数据便跟后,根据CounterStore.js 提供的getCounterValues接口返回变更后的数据。
Flux 的优缺点:
- 单向数据流限制了model和view之间的混乱
- store之间依赖关系
- 难以进行服务端渲染
- store混杂了逻辑和状态
Redux
Flux的基本原则是“单向数据流”,Redux在此基础上强调三个基本原则:
- 唯一数据源(Single Source of Truth):整个应用只保持一个Store,所有组件的数据源就是这个Store上的状态。
- 保持状态只读(State is read-only):不直接修改状态,要修改Store的状态,必须要通过派发一个action对象完成。
- 数据改变只能通过纯函数完成(Changes are made with pure funtions):这里所说的纯函数是指reducer。reducer函数接受两个参数:reducer(state,action)。第一个参数state是当前的状态,第二个参数action是收受到的action对象,而reducer函数要做个事情就是根据state和action的值产生一个新的对象返回(返回的结果必须完全由参数state和action决定,而且不应产生任何副作用)。
Flux中更新状态的函数只有一个参数action,因为状态是由Store直接管理的,所以处理函数中会看到直接更新state.
CounterStore.dispatchToken = AppDispatcher.register((action)=>{ if(action.type === ActionTypes.INCREMENT){ counterValues[action.counterCaption]++; CounterStore.emitChange(); }else if(action.type === ActionTypes.DECREMENT){ counterValues[action.counterCaption]--; CounterStore.emitChange(); } });Redux中实现同样功能的reducer代码如下:reducer只负责计算状态,却并不负责存储状态。
import * as ActionTypes from './ActionTypes.js'; export default (state,action)=>{ const {counterCaption} = action; switch(action.type){ case ActionTypes.INCREMENT: return {...state,[counterCaption]:state[counterCaption]+1}; case ActionTypes.DECREMENT: return {...state,[counterCaption]:state[counterCaption]-1}; default: return state; } }
redux-basic 例子运行原理要点总结:
- 组件(Counter.js)负责1.在store上注册监停回调(回调为一般会涉及自身状态变化);2.派发相应的action
- Reducer,负责根据相应的reducer返回新的store(即使store发生改变,这会自动触发store上的通过组件(如:Counter.js)注册的)监听事件。
- store的创建需要依赖于reducer。createStore(reducer)
总结:在redux框架下一个React组件基本上是要完成以下两个功能,1.和Redux Store打交道,读取Store的状态,同时还要监听Store的状态改变;当Store状态发生改变时,需要更新组件状态,从而驱动组件重新渲染;当需要更新Store状态时,就要派发action对象。2.根据当前的props 和 state,渲染出用户界面。
redux-smart-dumb 例子运行原理要点总结:(将redux-basic例子中的组件的两个功能,将组件拆分为傻瓜组件和容器组件)
容器组件(聪明组件):负责承担第一个任务,即和Redux Store打交道,处于外层。
展示组件(傻瓜组件):承担第二个任务的组件,即只专心负责渲染界面。(一般可以简化为一个纯函数)
实际上让傻瓜组件无状态,是我们拆分的主要目的之一,傻瓜组件只需要根据props来渲染结果,不需要state。
可以发现CounterContainer和SummaryContainer代码有很多相同之处,可以进行公共抽取。
redux Context例子运行原理总结:
以redux上例子中,都是在组件中直接引入Store,这样会导致一些问题(第三方库、Store位置变动)。
尽量避免每一个组件单独引入Store,为了实现这个React提供了Context功能。我们可以通过一个全局Provider组件来提供应用所需的数据。
React Context API有较大跟新。https://doc.react-china.org/docs/context.html
老版本API:Provider和容器组件都须有必要的特殊声明。
新版API:提供了React.createContext、Provider/Consumer,和老版本形式上有很大区别
react-redux 例子总结:
上面的例子中我们改进react应用主要使用了两个方法:1.将组件拆分为容器组件和傻瓜组件;2.使用React 的Context提供一个所有组件可以直接访问的Context。这两个优化中套路较多(即样板代码较多),于是就有了react-redux链接库,来简化操作。
connect:链接容器组件和傻瓜组件,主要完成两件事
- mapStateToProps(state,ownProps):将Store上的状态转化为内层傻瓜组件的prop
- mapDispatchToProps(dispatch,ownProps):将内层傻瓜组件的用户动作转化为派送给给Store的动作。
Provider:提供包含store的context
react-redux TodoList 目录结构:
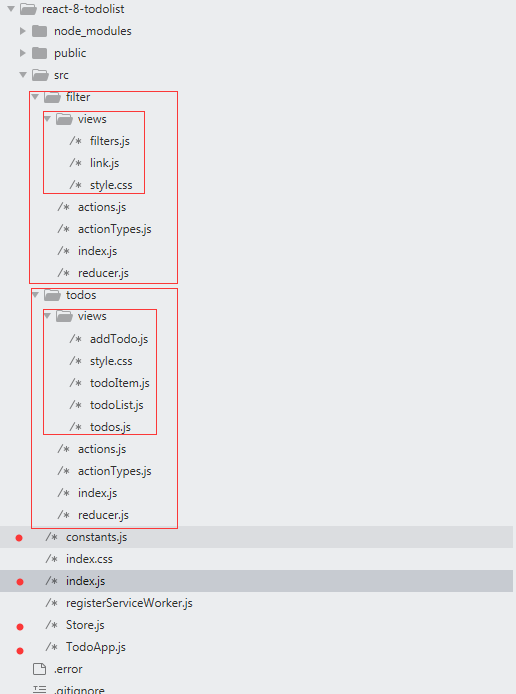
- actionTypes.js:定义action类型
- actions.js:定义action 构造函数,决定了这个功能模块可以接受的动作
- reducer.js:定义如何响应action.js中定义的动作
- views 目录:包含这个功能模块中所有的react组件,包括傻瓜组件和容器组件
- index.js :把所有角色导入,然后统一导出
我们将 TodoList 应用分为todos和filter两个模块,可以预期这两个模块间会有依赖关系,如filter模块想要使用todos的action构造函数和视图。
//若我们直接在filter模块中引用todos的action和视图, //这会让filter模块依赖于todos的内部结构,不合理 import * as actions from '../todos/actions.js' import view from '../todos/views/todos.js'